实战:Cursor 总是瞎编 API?用 Marker + PDF 自制 Skills 治好它的“幻觉”
最近在写一个对接 api-football 的 Python 脚本,本来想着有 Cursor 加持应该分分钟搞定。结果写着写着发现不对劲:Cursor 这家伙虽然代码写得溜,但对这个特定 API 的细节完全是在“凭感觉”写。
参数名瞎编、Endpoint 记错、返回结构臆想……典型的 AI 幻觉。
我意识到,光靠它自己“脑补”是不行了,得把官方文档喂给它。于是,一场从爬虫到 OCR 的“文档搬运”折腾之旅开始了。
第一回合:自动化工具的滑铁卢 (Skill-Seekers)
既然是为了给 AI 喂饭,我首先想到的就是专门干这个的工具。听说 skill-seekers 不错,能自动爬取文档并整理成 AI 易读的格式。
兴冲冲地配置好,运行!
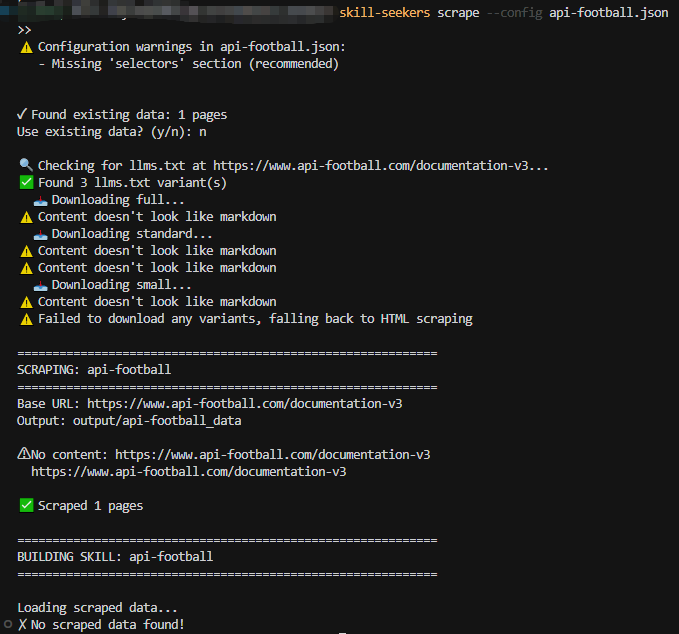
结果……就这?
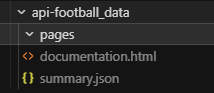
Output 目录里就一个孤零零的 HTML 和一个没啥用的 JSON。不知道是不是工具配置的问题,反正第一招直接折戟。心态有点小崩。
第二回合:另辟蹊径 (PDF + PyMuPDF4LLM)
既然自动爬取行不通,那就用最原始的办法:把网页存成 PDF,再转回 Markdown。
但在存 PDF 之前,有个小坑。api-football 的文档页面里,代码示例默认可能是 cURL 或者 PHP,我需要 Python 的示例。如果直接打印,很多代码块都不是我想要的。
1. JS 脚本“预处理”
我写了一段简单的 JavaScript 代码,在浏览器控制台里跑了一下,遍历页面上所有的 Code Switcher 按钮,强制把它们都点选到 Python 这一栏。
确认所有示例代码都变成 Python 后,右键 -> 打印 -> 另存为 PDF。
API-Football - Documentation.pdf
2. 轻量级转换尝试
拿到了 PDF,我先试了个轻量级的库 pymupdf4llm。
import pymupdf4llm
import pathlib
# 替换成你下载的 PDF 文件名
pdf_path = fr"API-Football - Documentation.pdf"
output_path = "football_skill.md"
print(f"🔄 正在转换 {pdf_path}...")
# 核心代码就这一行,它会自动把表格转为 Markdown 表格
md_text = pymupdf4llm.to_markdown(pdf_path)
# 保存文件
pathlib.Path(output_path).write_bytes(md_text.encode())
print(f"✅ 转换完成!已保存为: {output_path}")
跑得倒是挺快,输出也有了。但是打开一看,格式有点乱,表格错位,代码块的缩进也稀里糊涂的。
这种质量喂给 Cursor,估计它还得消化不良,搞不好还会产生新的误解。
第三回合:祭出大杀器 (Marker)
看来得动真格的了。我想到了 Marker。
这玩意儿号称 PDF 转 Markdown 的“大杀器”,支持深度学习模型进行布局分析、公式识别和表格处理。虽然重了点,但为了质量,拼了。
漫长的等待
安装好环境,加载模型。好家伙,这模型加载是真慢,而且对显存/内存也有要求。
整个转换过程,从加载模型到跑完,足足花了 50 分钟!

# 简单的调用命令示例
marker_single ".\API-Football - Documentation.pdf"
效果惊艳
虽然等得花儿都谢了,但打开输出的文件那一刻,我觉得值了。

API-Football - Documentation.md
- 排版完美:标题层级清晰,正文段落分明,看着就舒服。
- 代码块精准:之前用 JS 切换出来的 Python 代码块,被完美地包裹在
python标记里,缩进也没乱。 - 图片定位:文档里的示意图、架构图,位置插得严丝合缝。
虽然仔细看还是有那么一点点小瑕疵(比如极个别特殊符号),但完全不影响阅读和理解。这质量,绝对是 S 级 的语料。
最终章:喂给 Cursor
拿到了这份高质量的 Markdown 文档,我直接把它丢进了 Cursor 的项目里,做成 Skills。
见证奇迹的时刻:
我再次让 Cursor 写一个获取比赛数据的函数。
这一次,它没有再瞎编参数。
它准确地使用了 v3/fixtures 端点,参数里的 season 和 league 传得明明白白。
更重要的是,它知道了 API 的边界——它知道哪些数据是这个端点给不了的,需要去调另一个端点,而不是像之前那样在这个函数里硬造字段。
总结
如果你也遇到 Cursor 对某个私有库或特定 API 不熟悉的情况,强烈建议自己动手制作 Skills。
- 自动化爬虫(Skill-Seekers 等)先试试,能行最好,省时省力。
- 不行就转 PDF。记得先用 JS 把网页上的动态内容(如代码语言)调整好,这一步很关键。
- 追求质量用 Marker。虽然慢,但出来的 Markdown 结构化程度极高,对 AI 理解上下文非常有帮助。
磨刀不误砍柴工,花 50 分钟转文档,省下的是后面几小时 Debug 幻觉代码的时间。这波操作,不亏!